EECS2030 Lab 04
Oct 23, 2019
Due: Nov 6, 2019 before 11:59PM
Introduction
The purpose of this lab is to implement a simple LZW-based encoder/decoder using collections (specifically, maps and lists).
Before you begin
The API for the class that you need to implement can be found here.
The project file for this lab can be found here.
A copy of the Java API can be found here.
The Lempel-Ziv-Welch (LZW) compression
The LZW algorithm is a universal lossless data compression algorithm created by Abraham Lempel, Jacob Ziv, and Terry Welch. It is a simple compression algorithm that stores character patterns in a dictionary along with a index value (code). As an input sequence is parsed from start to finish, the codes from the dictionary are used in place of the character patterns, resulting in an encoded form of the input sequence. This method is used in the Unix "compress" utility, and in the GIF image file format.
During the parsing process a sliding window (beginning with the first character), stretches/grows
to consider progressively larger character patterns (i.e. sequences of 2 characters, then 3, etc.).
See the red window in (Figure 1). If a larger pattern is not yet in the dictionary, it is added to the
dictionary for future consideration (blue stretched window considers and adds "ab" to dictionary). The largest
pattern found so far (before adding the new pattern to the dictionary), is used the encoding (shown in green).
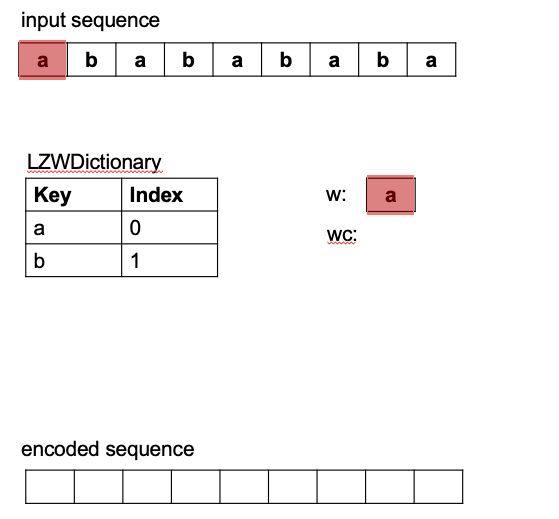
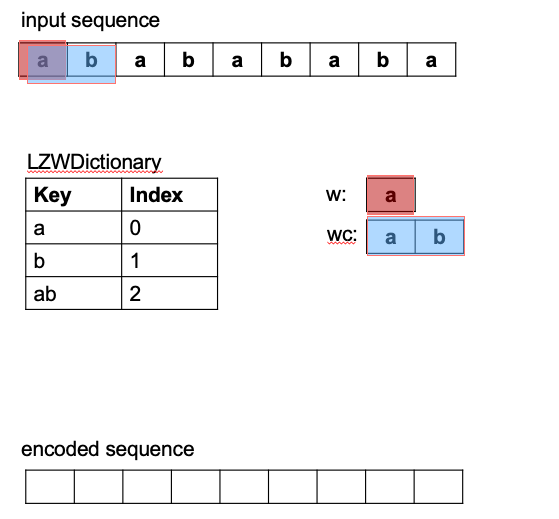
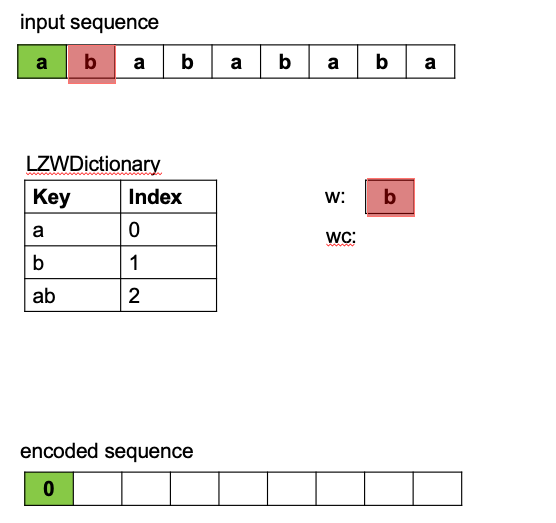
The sliding window then resets to the next character and the process repeats until the sliding window reaches
the end of the input sequence. As larger patterns are re-encountered, the window will keep stretching to consider
progressively larger character patterns.. resulting in larger patterns being added to the dictionary.
A short animation below shows the full encoding process for a simple input sequence.

The LZW principle ultimately works by capturing and exploiting any pattern redundancy in a sequence to be encoded. Whenever longer patterns repeat they can be encoded by a single code from the dictionary. This results in a shorter set of codes representing the original sequence, hence, the encoded form becomes a compressed version of the input. In the above example, the encoding replaces 9 characters from the input sequence, with 5 of the 6 character patterns collected in the dictionary. This results in ~9/5 compression ratio.
LZW Algorithm (encoding)
The method begins with a dictionary of patterns of length one (e.g. single, unique characters from an input string of characters), then parses the input sequence by attempting to merge adjacent elements of the sequence to see if they exist in the dictionary. If any subsequence is found not to be in the dictionary, an index corresponding to the longest sequence found so far will be "emitted" from the dictionary (outputted to the encoding).
A high level view of the encoding algorithm is shown here:
- Initialize the dictionary with unique single character strings
- Let W = first input character
- WHILE not end of input sequence
- C = next input character
- Let WC = W + C (i.e. append C to W)
- IF WC is in the dictionary, expand W to include C
- W = WC
- ELSE
- output the code for W (index from the dictionary)
- add WC to the dictionary
- shift the window along: W = C
- END WHILE
- Output code for W (the last pattern found)
LZW Algorithm (decoding)
Decoding a sequence follows a similar approach, beginning with the same initial dictionary. The character patterns are re-built and added to the dictionary as the encoded indexes are parsed. These patterns are then also used in the decoding.
A high level view of the decoding algorithm is shown here:
- Initialize the dictionary with unique single character strings
- Let PREV = first input code
- Output the pattern for PREV (from dictionary) to the decoded result
- WHILE not end of input sequence
- NEXT = next input code
- IF NEXT is in the dictionary
- Let S = the pattern for NEXT (from dictionary)
- ELSE
- Let S = the pattern for PREV (from dictionary)
- Let C = first character of S (PREV pattern)
- S = S + C
- Output S to the decoded result
- Let ENTRY = the pattern for PREV + first character of S
- Add ENTRY to the dictionary
- PREV = NEXT
- END WHILE
Programming exercise
There are two classes to implement for this programming exercise. The first task is to implement a dictionary class (that will manage a dictionary for storing and retrieving character patterns). The second is a class that will use this dictionary to encode and decode a given input sequence of characters. The API for the classes that you need to implement can be found here.
- Download and import the project using the link provided at the top of this webpage
- Implement the API for the
LZWDictionaryclass first. This class opts for a dictionary implementation that uses both a list and a map collection together. This simplifies the ability to add unique patterns when encoding and have fast retrieval of patterns when decoding. Read the class description in the API for more information. - The dictionary uses a map to store a collection of unique character patterns. Initially, the dictionary is created using individual characters (without duplicates). The dictionary then supports the possibility of adding larger patterns that combine two or more of these individual characters. Each pattern has an index associated with it when added. The index reflects the order in which the pattern was added to the dictionary. The list also stores a copy of the pattern in this same order, so the index relates to a pattern's position in the list.
- First, implement the fields and accessor methods
getMap()andgetList()methods along with your constructor. These will be needed for the tester to properly evaluate your constructor - Once this is done, work through the other methods and implement them. The order of tests in the tester is a good order to follow
- Do not attempt to build the second class
LZWCompressoruntil theLZWDictionaryclass is fully working - For the
LZWCompressorclass, make sure the accessors and constructor are built and working before attempting other methods. Note the constructor uses a string to create and initialize an LZWDictionary object (which it stores as a field). The string serves as the sequence to be encoded/decoded, and should also be stored in a field. The format for how you store the input sequence is up to you, however it might be more convenient to store in a format that makes it simple to iterate over/parse during the encode/decode methods - Work on the
encode()method first, and make sure that is working, then complete thecompressionRatio()method (as this only requires encode) - Work on the
decode()method last. Some test cases from the Tester are also included in the main, in case you wish to run the LZWCompressor class directly and observe output to the console.
Submit for students NOT working in a group
If you are not working in a group, submit your solution using the submit command. Remember that
you first need to find your workspace directory, then you need to find
your project directory. In your project directory, your files will be
located in the directory src/eecs2030/lab4
submit 2030 lab4 LZWDictionary.java LZWCompressor.java
Submit for students working in a group
If you are working in a group, create a plain text file named
group.txt. You can do this in eclipse using the menu
File -> New -> File. Type your login names into the file
with each login name on its own line. For example, if the students
with login names
rey, finn, and dameronp,
worked in a group the contents of group.txt would
be:
rey finn dameronp
Submit your solution using the submit command. Remember that
you first need to find your workspace directory, then you need to find
your project directory. In your project directory, your files will be
located in the directory src/eecs2030/lab4
submit 2030 lab4 LZWDictionary.java LZWCompressor.java group.txt